利用 AST 技术还原 JavaScript 混淆代码
原文作者:K哥爬虫 | 发布于 2022-04-28


一、什么是 AST
AST(Abstract Syntax Tree),即抽象语法树,是源代码语法结构的树状表现形式,树上的每个节点都对应源代码中的一种语法结构。AST 并非某一种语言独有,JavaScript、Python、Java、Golang 等几乎所有编程语言都有对应的语法树。
可以把 JavaScript 代码想象成一台精密运转的机器,通过 AST 解析,我们能像拆解玩具一样深入了解它的每个零部件,然后按照自己的意愿重新组装。
AST 的应用场景
AST 的用途非常广泛,并不只是为逆向而生:
- IDE 功能:语法高亮、代码检查、自动格式化
- 代码转译:Babel 将 ES6+ 语法转换为 ES5
- 代码压缩:Uglify、Terser 等工具
- 逆向解混淆:还原被混淆的 JS 代码 ← 本文重点
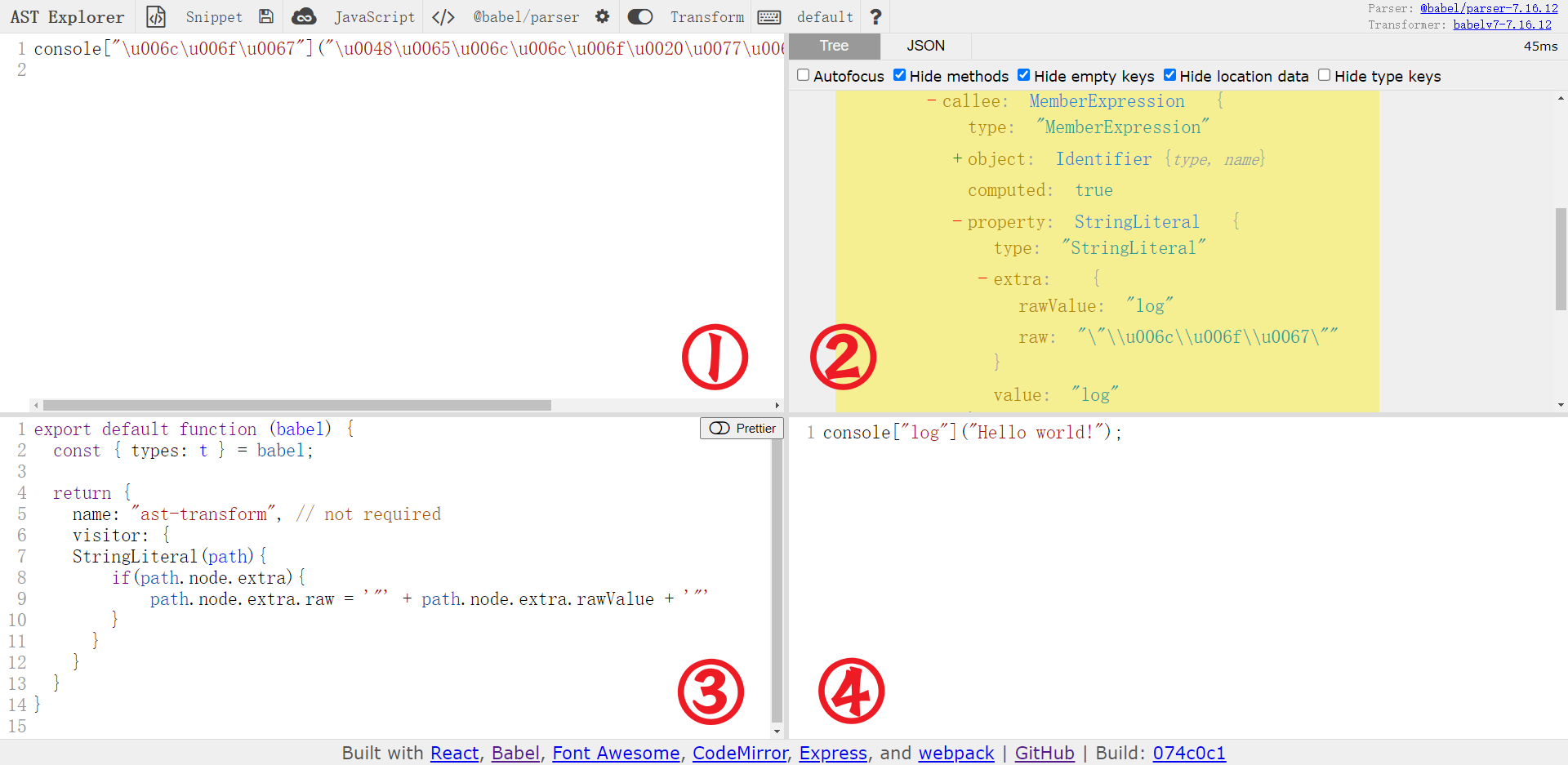
在线工具
推荐使用 https://astexplorer.net/ 在线可视化 AST 结构:
- 区域①:输入源代码
- 区域②:对应的 AST 语法树
- 区域③:转换代码(可对语法树进行增删改查)
- 区域④:转换后生成的新代码
顶部可以选择语言、编译器(Acorn、Espree、Esprima、Recast、Uglify-JS 等),本文以使用最广泛的 Babel 为例。
二、AST 在编译中的位置
在编译原理中,编译器转换代码通常经历三个阶段:
源代码 → 词法分析 → 语法分析 → AST → 代码生成 → 目标代码
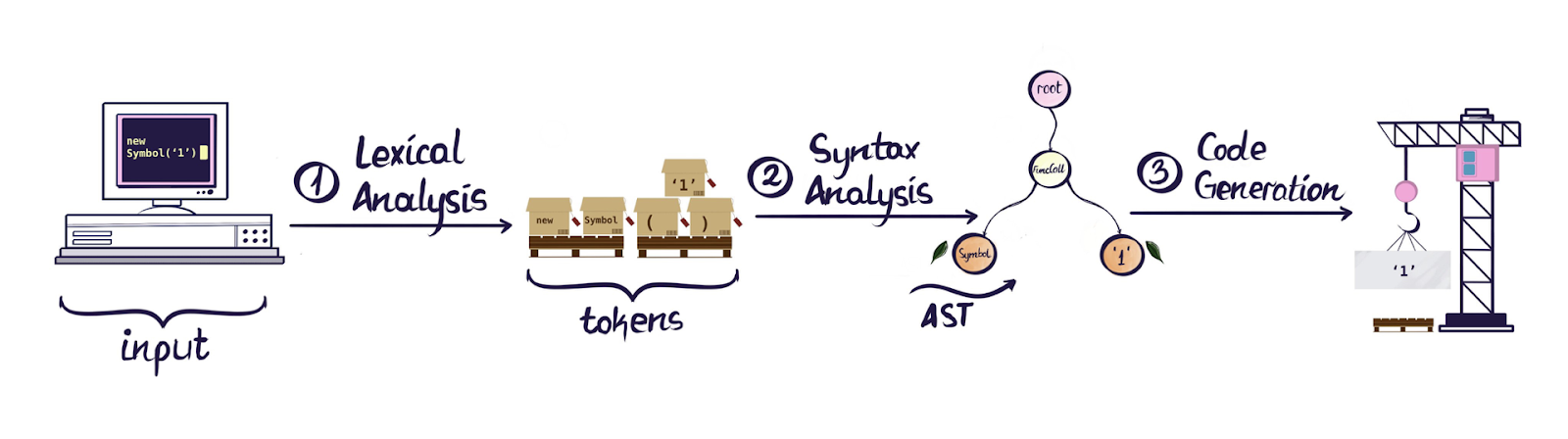
1. 词法分析(Lexical Analysis)
词法分析是编译的第一阶段,从左到右逐字符读取源代码,根据构词规则识别单词,生成 Token 符号流。
例如 isPanda(' ') 会被拆分为:
isPanda → 标识符( → 左括号' ' → 字符串字面量) → 右括号

2. 语法分析(Syntax Analysis)
语法分析在词法分析的基础上,将 Token 序列组合成各类语法短语,建立节点间的依赖和嵌套关系,最终构成树状结构,即 AST 语法树。
例如:
isPanda(' ') → ExpressionStatement(表达语句)isPanda() → CallExpression(函数调用表达式)' ' → Literal(字面量)

3. 代码生成(Code Generation)
最后一步,将 AST 语法树转换回可执行代码。在转换之前,我们可以直接操作语法树,进行增删改查,这正是 AST 解混淆的核心所在。

三、Babel 工具链介绍
Babel 是目前最主流的 JavaScript 编译器,内置了丰富的 AST 操作 API。
安装
npm install @babel/core @babel/parser @babel/traverse @babel/generator @babel/types
核心功能包
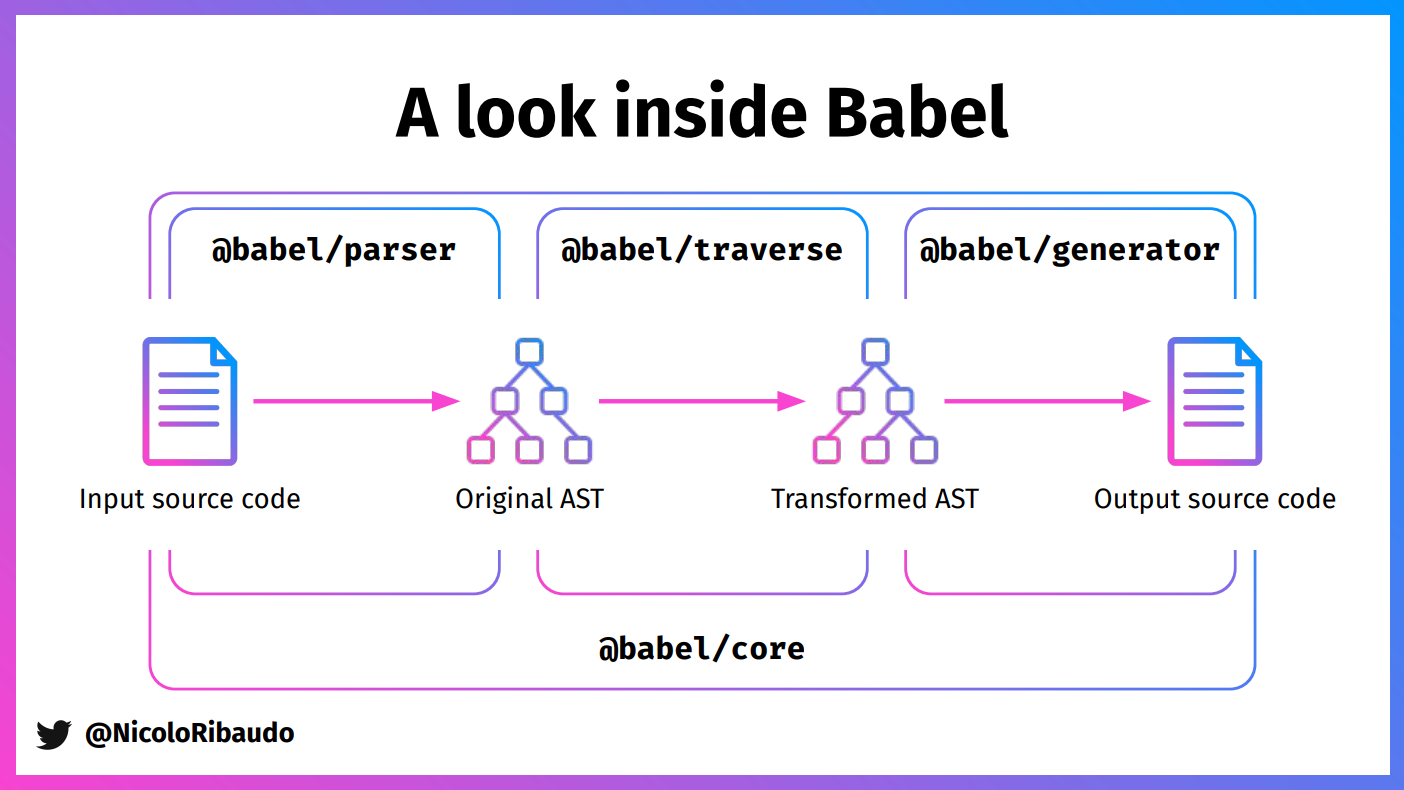
@babel/parser — 解析代码为 AST
提供两个核心方法:
parser.parse(code, [options]):解析完整 JS 代码parser.parseExpression(code, [options]):解析单个表达式(性能更好)
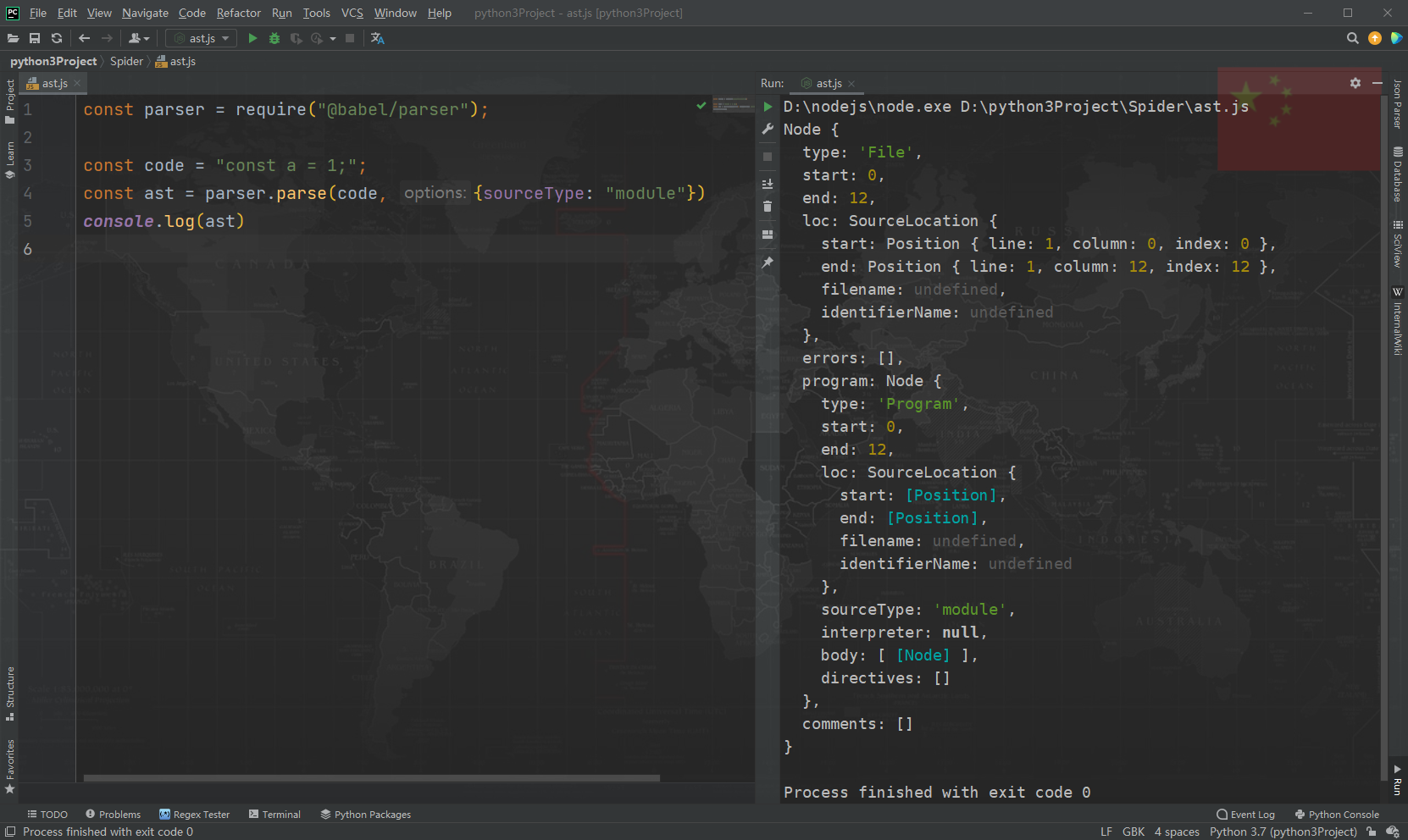
const parser = require("@babel/parser");
const code = "const a = 1;";
const ast = parser.parse(code, { sourceType: "module" });
console.log(ast);
输出的 AST 结构与 astexplorer.net 解析结果完全一致:
@babel/generator — 将 AST 还原为代码
提供 generate(ast, [options], code) 方法。
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const code = "const a = 1;";
const ast = parser.parse(code, { sourceType: "module" });
// 修改变量名 a → b,值 1 → 2
ast.program.body[0].declarations[0].id.name = "b";
ast.program.body[0].declarations[0].init.value = 2;
const result = generate(ast, { minified: true });
console.log(result.code); // 输出:const b=2;
其中 ast.program.body[0].declarations[0].id.name 是变量 a 在 AST 中的路径:
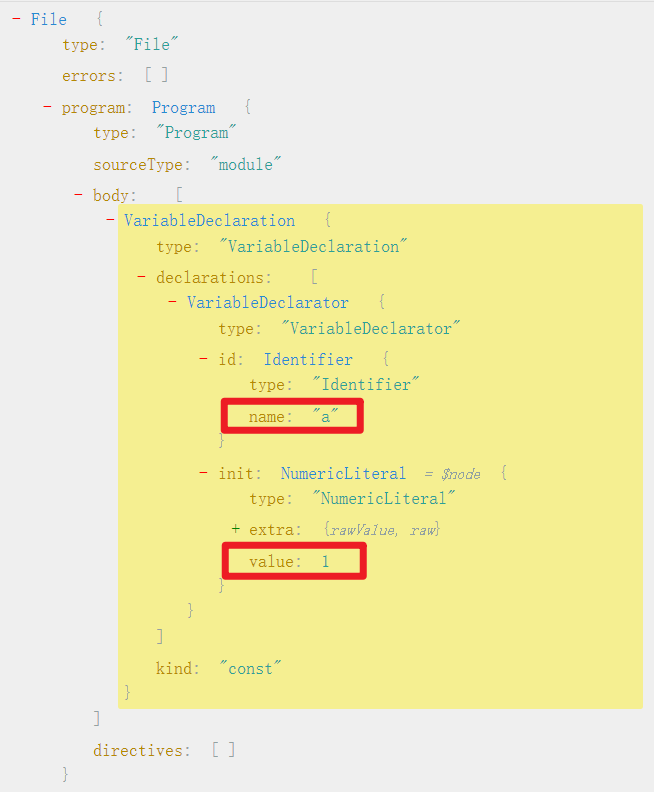
@babel/traverse — 遍历并修改节点
traverse 配合 visitor 对象使用,可以批量处理同类型节点:
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const traverse = require("@babel/traverse").default;
const code = `
const a = 1500;
const b = 60;
const c = "hi";
const d = 787;
const e = "1244";
`;
const ast = parser.parse(code);
const visitor = {
NumericLiteral(path) {
path.node.value = (path.node.value + 100) * 2;
},
StringLiteral(path) {
path.node.value = "I Love JavaScript!";
}
};
traverse(ast, visitor);
const result = generate(ast);
console.log(result.code);
对应的 AST 节点类型:
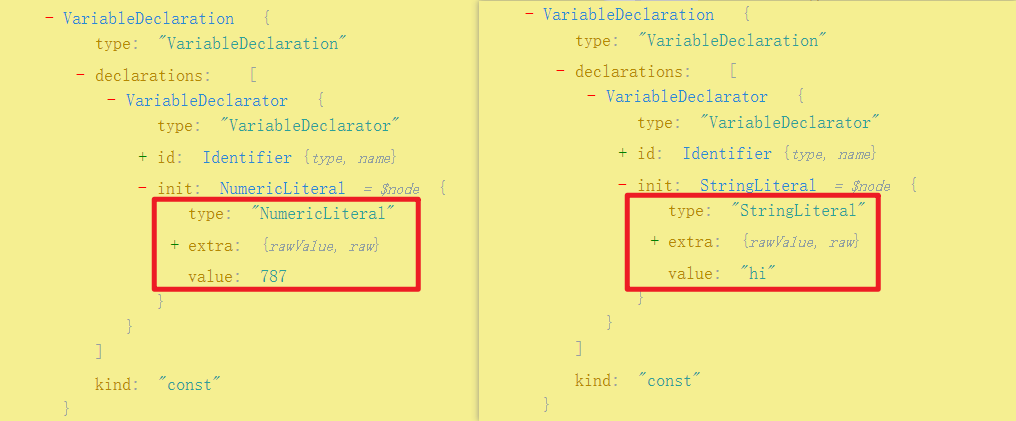
输出结果:
const a = 3200;
const b = 320;
const c = "I Love JavaScript!";
const d = 1774;
const e = "I Love JavaScript!";
visitor 的多种写法
以下四种写法效果完全相同,可根据习惯选择:
// 写法一:简写方法
const visitor = {
NumericLiteral(path) { path.node.value = 0; },
StringLiteral(path) { path.node.value = ""; }
};
// 写法二:function 关键字
const visitor = {
NumericLiteral: function(path) { path.node.value = 0; },
StringLiteral: function(path) { path.node.value = ""; }
};
// 写法三:enter/exit 钩子
const visitor = {
NumericLiteral: { enter(path) { path.node.value = 0; } },
StringLiteral: { enter(path) { path.node.value = ""; } }
};
// 写法四:统一入口 + 类型判断
const visitor = {
enter(path) {
if (path.node.type === "NumericLiteral") path.node.value = 0;
if (path.node.type === "StringLiteral") path.node.value = "";
}
};
提示:enter 在进入节点时触发(默认),exit 在退出节点时触发。多个类型共用同一处理逻辑时,可用 | 连接:"NumericLiteral|StringLiteral"(path) {...}
@babel/types — 构建新 AST 节点
当需要新增节点时,使用 @babel/types。方法名与 AST 节点类型一致,首字母小写。
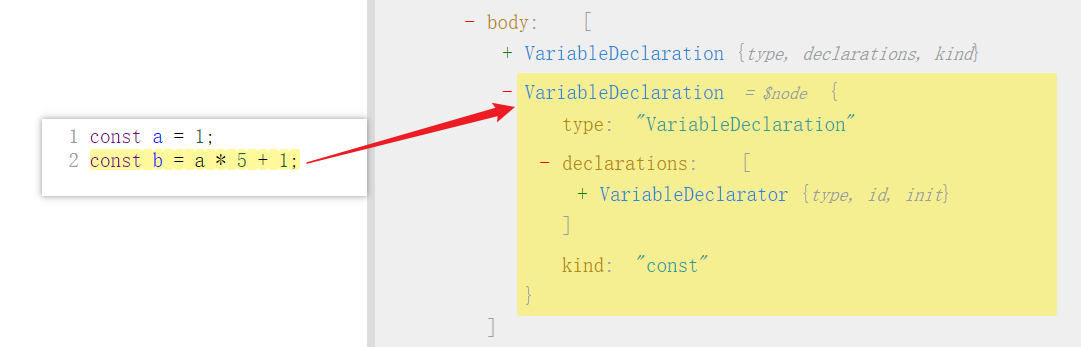
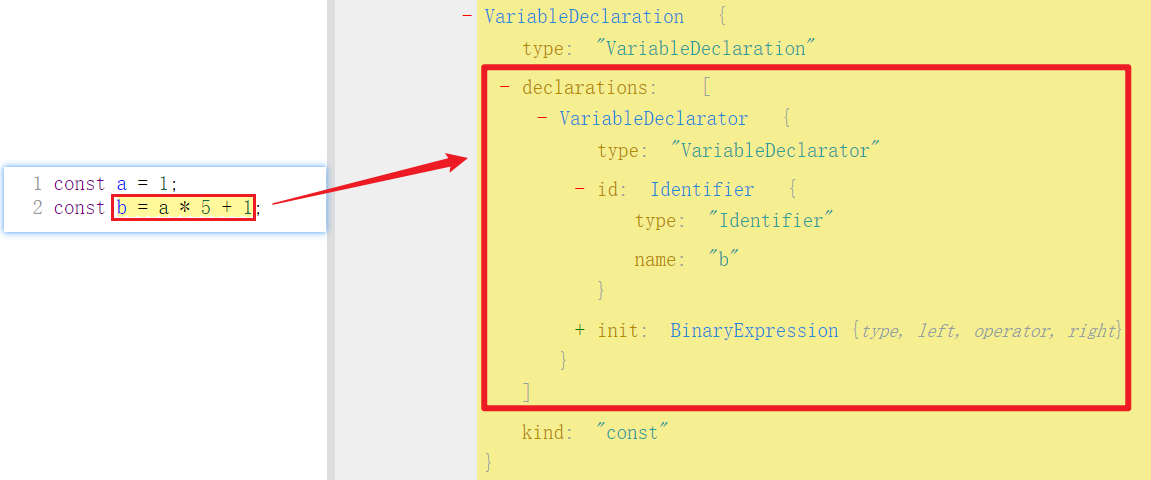
目标:将 const a = 1; 扩展为 const a = 1; const b = a * 5 + 1;
先观察目标 AST 结构:
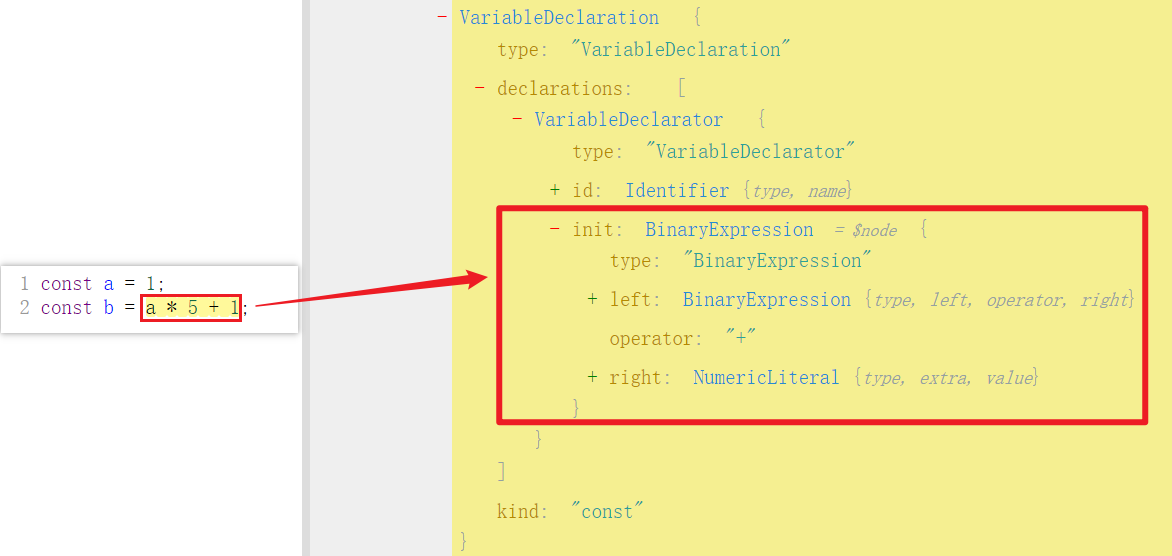
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const traverse = require("@babel/traverse").default;
const types = require("@babel/types");
const code = "const a = 1;";
const ast = parser.parse(code);
const visitor = {
VariableDeclaration(path) {
// 构造 a * 5
let left = types.binaryExpression("*", types.identifier("a"), types.numericLiteral(5));
// 构造 a * 5 + 1
let init = types.binaryExpression("+", left, types.numericLiteral(1));
// 构造 b = a * 5 + 1
let declarator = types.variableDeclarator(types.identifier("b"), init);
// 构造 const b = a * 5 + 1
let declaration = types.variableDeclaration("const", [declarator]);
// 在当前节点后插入
path.insertAfter(declaration);
// 停止遍历,防止无限循环
path.stop();
}
};
traverse(ast, visitor);
const result = generate(ast);
console.log(result.code);
运行结果:
技巧:不确定方法参数时,直接在 IDE 中按住 Ctrl 点击方法名查看源码,比查文档更直观。
四、常见混淆还原实战
4.1 Unicode 字符串还原
混淆代码将字符串替换为 Unicode 编码:
console['\u006c\u006f\u0067']('\u0048\u0065\u006c\u006c\u006f\u0020\u0077\u006f\u0072\u006c\u0064\u0021')
观察 AST,Unicode 编码存储在 extra.raw 中,而 value 已经是正常字符:
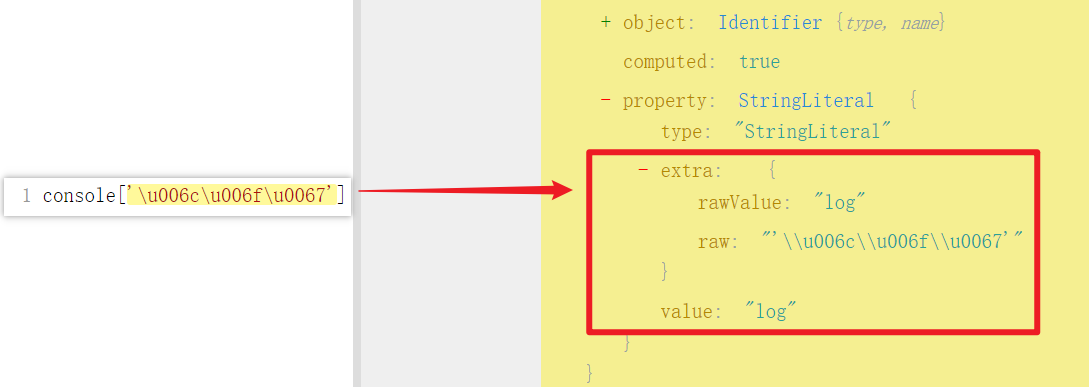
还原方案:删除 extra.raw,让 generator 使用 value 重新生成:
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const traverse = require("@babel/traverse").default;
const code = `console['\u006c\u006f\u0067']('\u0048\u0065\u006c\u006c\u006f\u0020\u0077\u006f\u0072\u006c\u0064\u0021')`;
const ast = parser.parse(code);
const visitor = {
StringLiteral(path) {
delete path.node.extra.raw; // 删除 raw,保留 value
}
};
traverse(ast, visitor);
console.log(generate(ast).code);
// 输出:console["log"]("Hello world!");
4.2 表达式计算还原
混淆代码将简单值替换为复杂表达式:
const a = !![]+!![]+!![]; // 实际是 3
const b = Math.floor(12.34 * 2.12) // 实际是 26
const c = 10 >> 3 << 1 // 实际是 2
const g = 20 < 18 ? '未成年' : '成年' // 实际是 '成年'
还原方案:使用 path.evaluate() 自动计算表达式结果:
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const traverse = require("@babel/traverse").default;
const types = require("@babel/types");
const code = `
const a = !![]+!![]+!![];
const b = Math.floor(12.34 * 2.12);
const c = 10 >> 3 << 1;
const g = 20 < 18 ? '未成年' : '成年';
`;
const ast = parser.parse(code);
const visitor = {
"BinaryExpression|CallExpression|ConditionalExpression"(path) {
const { confident, value } = path.evaluate();
if (confident) {
path.replaceInline(types.valueToNode(value));
}
}
};
traverse(ast, visitor);
console.log(generate(ast).code);
输出结果:
const a = 3;
const b = 26;
const c = 2;
const g = "成年";
节点替换方法说明:
replaceWith:用一个节点替换replaceWithMultiple:用多个节点替换replaceInline:自动判断,相当于前两者的合并
4.3 删除未使用变量
混淆代码中常有大量无用变量干扰分析:
const a = 1;
const b = a * 2;
const c = 2; // c 未被使用
const d = b + 1;
const e = 3; // e 未被使用
console.log(d);
还原方案:通过 scope.getBinding() 检查变量是否被引用:
const visitor = {
VariableDeclarator(path) {
const binding = path.scope.getBinding(path.node.id.name);
// 被修改过的变量不能删除
if (!binding || binding.constantViolations.length > 0) return;
// 未被引用则删除
if (!binding.referenced) {
path.remove();
}
}
};
scope.getBinding() 返回的关键属性:
处理结果(c、e 被删除):
const a = 1;
const b = a * 2;
const d = b + 1;
console.log(d);
4.4 删除冗余 if-else 逻辑
混淆代码中常有大量永远不会执行的分支:
const example = function () {
let a;
if (false) {
a = 1; // 永远不执行
} else {
if (1) {
a = 2; // 实际执行这里
} else {
a = 3; // 永远不执行
}
}
return a;
};
观察 AST 结构(test 为判断条件,consequent 为 if 分支,alternate 为 else 分支):

还原方案:
const traverse = require("@babel/traverse").default;
const types = require("@babel/types");
const visitor = {
IfStatement(path) {
const test = path.node.test;
// 只处理布尔字面量和数字字面量作为条件的情况
if (!types.isBooleanLiteral(test) && !types.isNumericLiteral(test)) return;
if (test.value) {
// 条件为真:保留 if 分支
path.replaceInline(path.node.consequent.body);
} else {
// 条件为假:保留 else 分支(若有),否则删除整个节点
if (path.node.alternate) {
path.replaceInline(path.node.alternate.body);
} else {
path.remove();
}
}
}
};
处理结果(冗余分支全部清除):
const example = function () {
let a;
a = 2;
return a;
};
4.5 switch-case 反控制流平坦化
控制流平坦化是最常见的混淆手段之一,通过 while-switch-case 打乱代码执行顺序:
const _0x34e16a = '3,4,0,5,1,2'['split'](',');
let _0x2eff02 = 0x0;
while (!![]) {
switch (_0x34e16a[_0x2eff02++]) {
case '0': let _0x38cb15 = _0x4588f1 + _0x470e97; continue;
case '1': let _0x1e0e5e = _0x37b9f3[_0x50cee0(...)]; continue;
case '2': let _0x35d732 = [...]; continue;
case '3': let _0x4588f1 = 0x1; continue;
case '4': let _0x470e97 = 0x2; continue;
case '5': let _0x37b9f3 = 0x5 || _0x38cb15; continue;
}
break;
}
还原思路:
- 获取控制流数组(
'3,4,0,5,1,2'.split(','))
- 按数组顺序依次取出对应
case 的内容
- 删除
continue 语句
- 用还原后的代码替换整个
while 节点
还原代码(方法一:通过前置兄弟节点获取数组):
const parser = require("@babel/parser");
const generate = require("@babel/generator").default;
const traverse = require("@babel/traverse").default;
const types = require("@babel/types");
const fs = require("fs");
const code = fs.readFileSync("code.js", { encoding: "utf-8" });
const ast = parser.parse(code);
const visitor = {
WhileStatement(path) {
const switchNode = path.node.body.body[0];
const arrayName = switchNode.discriminant.object.name;
let array = [];
// 获取 while 前面所有兄弟节点
path.getAllPrevSiblings().forEach(prevNode => {
const { id, init } = prevNode.node.declarations[0];
if (arrayName === id.name) {
// 模拟执行 '3,4,0,5,1,2'['split'](',')
const object = init.callee.object.value;
const property = init.callee.property.value;
const argument = init.arguments[0].value;
array = object[property](argument);
}
prevNode.remove(); // 删除前置变量声明
});
// 按正确顺序拼接 case 内容
let replace = [];
array.forEach(index => {
const consequent = switchNode.cases[index].consequent;
// 删除末尾的 continue 语句
if (types.isContinueStatement(consequent[consequent.length - 1])) {
consequent.pop();
}
replace = replace.concat(consequent);
});
path.replaceWithMultiple(replace);
}
};
traverse(ast, visitor);
console.log(generate(ast).code);
还原结果(乱序代码恢复为顺序执行):
let _0x4588f1 = 0x1;
let _0x470e97 = 0x2;
let _0x38cb15 = _0x4588f1 + _0x470e97;
let _0x37b9f3 = 0x5 || _0x38cb15;
let _0x1e0e5e = _0x37b9f3[_0x50cee0(0x2e0, 0x2e8, 0x2e1, 0x2e4)];
let _0x35d732 = [_0x388d4b(-0x134, -0x134, -0x139, -0x138)](_0x38cb15 >> _0x4588f1);
五、学习资源
六、总结
Babel 国内资料相对较少,建议多看源码 + 对照 astexplorer.net 可视化调试,耐心逐层分析。本文案例均为基础操作,实际逆向中还需根据具体混淆方式灵活调整,后续将通过实战案例进一步深入。